

 Rapid Ext JS
Rapid Ext JS



Sencha Test Examples – Part 2
July 14, 2016
189 Views
Introduction
Sencha Test provides developers and test engineers with a complete platform to perform functional testing of single page applications. Tests can be written and executed locally on the engineer’s machine and then easily replicated in a continuous integration (CI) environment. As in the Part 1 of this series, this is best illustrated by walking through some examples.
Functional Tests
Functional testing is a form of black-box testing that ensures a system meets its functional requirements. Functional tests load the application and drive it through particular workflows to make sure the application does what it’s supposed to do. Given the asynchronous nature of JavaScript and web applications, these workflows are often time consuming to test properly.
We’ll see in these examples how Sencha Test can greatly simplify this process using the Futures API. For more information, check out this article on Futures.
The Application
The examples in this article use the Admin Dashboard application template from Ext JS 6 as the test subject (see the live demo).
Test Organization
The tests for the Admin Dashboard application are organized in three scenarios: Unit, Functional, and Integration. The tests in the Functional scenario are further organized into files and folders based on the navigational structure of the application itself.
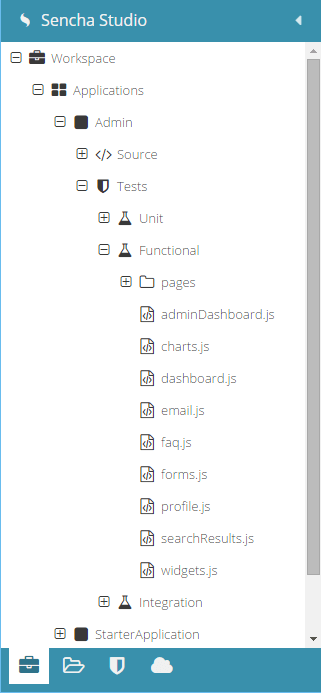
Testing Views
In this single page application, each view in the application has an associated file with its test file. Every .js file in the tests folder is a suite, as it can contain multiple test cases. Let’s start with adminDashboard.js in the Functional scenario.
Starting Point
To ensure that each test in the suite has a consistent starting point, the Jasmine beforeEach method is used:
beforeEach(function(){
Admin.app.redirectTo("#dashboard");
});
This is important if individual tests change the route using the tree list. We don’t want to worry about tests starting from a “random” application state.
The Page Object
Each view consists of various components that will be used across many different tests. The technique used to avoid repetitive code is a “page object” (learn more about “Keeping DRY” in this article). At the top of the test suite is the page object that provides useful methods like these:
var Dash = {
treeList: function () {
return ST.component('treelist');
},
hamburger: function () {
return ST.component('#main-navigation-btn');
},
menuItem: function (itemName) {
return ST.component('treelistitem[text=' + itemName + ']');
},
toolbarItem: function (itemName) {
return ST.button('toolbar button[href=#' + itemName + ']');
},
// ...
The methods of the page object return futures that are used to perform the various tests. Some methods (like treeList) take no arguments and return a future for a particular component. Other methods (such as menuItem) take a parameter that is used to complete the locator for the desired component. These methods make tests more readable and maintainable.
The Art of Identity
Perhaps the hardest part of functional testing is uniquely identifying the desired components. Page objects help by encapsulating this issue behind a set of methods. This way, the details of how a particularly meaningful item on the page will be located are never repeated. If the application changes and the method breaks, there is only one place to fix.
Of course, the best way to create stable functional tests is to work with the development team on an identity strategy for components. Without this cooperation, the entire test suite will always be “one refactor away” from a tidal wave of failures.
Locators
There are really two parts to each of the methods in the Page Object. Consider:
hamburger: function () {
return ST.component('#main-navigation-btn');
},
The two key parts are: the API called to create the future of the proper type (“ST.component” in this case); and the “locator” string passed to that method (“#main-navigation-btn”). The choice of API method should be determined by knowledge of the type of component involved. The locator string, however, requires more consideration. There are two general purpose formats for locator strings and an additional format designed for brevity and performance.
Composite Query
The Composite Query syntax is a combination of Ext JS Component Query syntax and CSS syntax (used by the DOM API). These both use the same basic syntax to describe components or elements. This is the recommended locator format to use because it maps closely to the component structure of an Ext JS application and the elements these components render.
The simplest way to understand Composite Query is to begin with CSS. When writing CSS selectors, you combine tag names, class names, and attribute filters to select matching elements. For example:
div.foo[title="Hello"]
The above CSS selector matches a div (the tag name) with a “foo” class and a “title” attribute with the value of “Hello”. The Component Query syntax works in the same manner, except that instead of tag names there are “xtypes” to identify the component type and properties:
panel[title="Hello"]
The above code selects an Ext JS panel component that has the “title” property value “Hello”. When these two pieces are combined (using “=>” to separate them), you have a Composite Query:
panel[title="Hello"] => div.foo
The above code selects a “div” with class of “foo” that is a descendant of a “panel” with “title” of “Hello”.
XPath
The second general purpose format is XPath. A locator string is recognized as XPath instead of Composite Query when the string starts with a “/” character. XPath only operates at the level of elements and will therefore be more complex to use when dealing with Ext JS component structures. A detailed exploration of XPath is beyond the scope of this article, but a simple example would be as follows:
//div[@id="mainDiv"]/span[2]
This code finds the second span that is an immediate child of a div with an “id” attribute of “mainDiv”.
At-Path
The “at-path” syntax is a very small subset of XPath with a slight twist to the first piece of the path. The above XPath would look like this as an at-path:
@mainDiv/span[2]
An at-path begins with the “@” symbol and the id of an element. Optionally, this can be followed by a series of slashes followed by tag names and ordinal offsets. The locator form is very clearly more dense than XPath and is very efficient at finding the starting element. From there, descent is also simple.
The format is only useful when the application offers meaningful IDs on important components and elements.
Writing Tests
Using futures and the page object, the individual tests are clean and expressive. Consider this test:
it('click to expand menu item', function(){
Dash.menuItem('Pages')
.and(function(menuItem){
expect(menuItem.isExpanded()).toBe(false);
})
.click()
.wait(function (menuItem) {
return menuItem.isExpanded();
})
.and(function(menuItem){
expect(menuItem.isExpanded()).toBe(true);
});
});
The logic flows as read from top to bottom. Even though the actions occur over time (for example, as animations complete), the test author does not have to be concerned with these delays.
Conclusion
If you have already read Part 1 of this series, you can see how unit and functional tests have a lot in common. The Jasmine and Sencha Test APIs, as well as the test runner, are all shared. So whether you start with unit tests or functional tests, you can always dabble in other forms without installing new tools or learning new APIs.
To see lots of other functional tests and the techniques they use, head over to the full example on GitHub. To watch the tests run on multiple browsers simultaneously, check out this video of an Admin Dashboard test.
Did you find the content helpful?
 0
0

 0
0

Latest Content

Ext JS 7.8 Has Arrived!
The Sencha team is pleased to announce the latest Ext JS version 7.8 release. Following…
May 13, 2024

React Apps Development Using ReExt with Ext JS Components
The world is moving fast towards online businesses. Businesses are established online via social media,…
May 1, 2024

How to Write Unit Tests with Sencha Test
In modern software development, unit testing has become an essential practice to ensure the quality…
April 19, 2024




