

 Rapid Ext JS
Rapid Ext JS



Using Fiddle 2 To Share Ext JS Code
December 7, 2016
181 Views
When Sencha Fiddle 1 was first released in 2013, the way we shared and tested Ext JS code was revolutionized. Prior to Sencha Fiddle, there wasn’t a standard way to share code that was constantly updated with each Ext JS release. Fiddle 1 was great, but the recently released Fiddle 2 is fantastic. In this article, I’ll show you the improvements we’ve made in Fiddle 2.
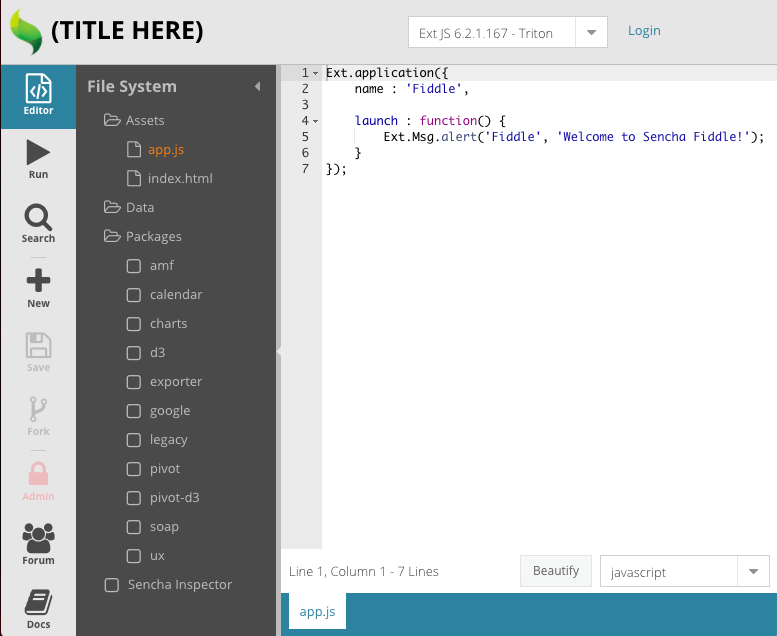
Like Local Development
In Fiddle 1, there was a limitation on how it ran the code. If you created multiple files, executing the code meant all of the source code from those files was concatenated in seemingly random order into a <script> node. While this worked and was performant, there was a downside. If you required other classes, as you normally would do in an application, you might have seen errors thrown in the console. Ext JS might have tried to load the file for that class after having been concatenated and your code might or might not have run.
Also, if you used mock data, the requests were hidden and just worked. There was no way to know what happened behind the scenes. If the response was incorrect (for what you or Ext JS wanted), there was no way to debug it.
To solve these issues, Fiddle 2 focuses on mimicking locally-developed code projects. When you run code in Fiddle 2, only “app.js” is automatically loaded for you via a <script> node. To load any other file, you can require the class just like you would locally. Ext JS will load the file via a real network request. This means if you open the browser’s dev tools and look at the network tab, you’ll see “app.js” and any other files you required. The same is true for data requests. When loaded, they are inspectable in the network requests.
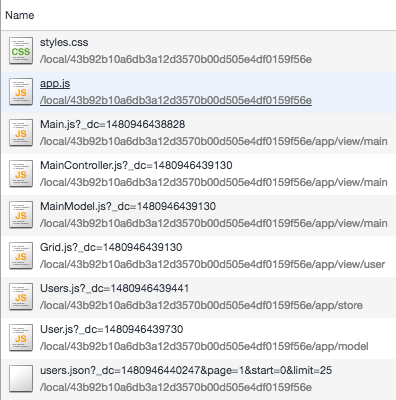
Improved Data Support
Ext JS applications have always been data rich. It’s one of the things Ext JS handles very well. In Fiddle 1, you could load JSON and XML assets. Fiddle 2 expands this feature to include plaintext and Ext Direct assets. Of course, these are inspectable in the browser’s dev tools.
To have good Ext Direct support, those assets need to have programmatic responses. With Fiddle 2, all data requests may optionally be dynamic responses – meaning you can provide JavaScript code that is executed on the server along with any parameters in the request. This is very useful if responses need to be tailored to the request. For example, a grid can remotely handle sorting when users click on the grid headers. The sort order can now be fully supported by providing the JavaScript code to sort the response. For more on dynamic data, please read the data guide.
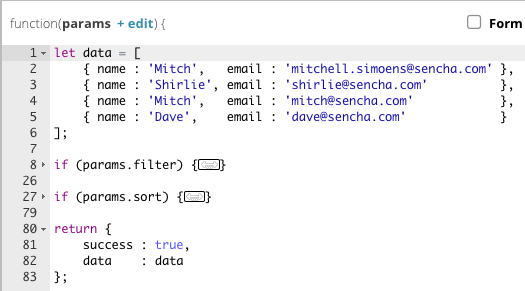
Another improvement is the implementation of data templates which can generate data for you. This is very handy if you need to generate lots of rows. For more on data templates, please read the data guide.

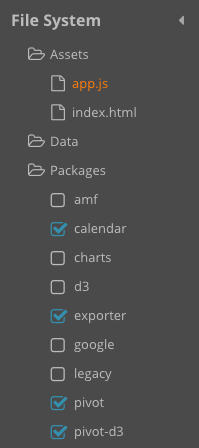
Framework Packages Support
Ext JS now has several Sencha code packages that add additional features such as the Pivot Grid. When Fiddle 1 was created, Ext JS didn’t make use of the package system the way it does today. Ext JS now has separate packages for the Calendar, Pivot Grid, D3, and more. Fiddle 2 introduces support for these framework packages. Furthermore, it’s incredibly simple to use these packages within Fiddle 2. To include a package, select its checkbox in the file tree. When the code is run, Fiddle will automatically include any JavaScript or CSS resources required by the package – no additional requirements.
Multi-monitor Support
One of my favorite new features is multi-monitor support. Some of us work in front of a computer with many monitors. And while running code side-by-side with the editor is handy, it can restrict the amount of space you have to view both the output and the code. With Fiddle 2, you can configure your settings to always open a new window when you run the code. This allows you to position that window on another monitor enabling you to be more productive. This also introduces other benefits. For example, if you are debugging your code, you won’t need to target that iframe to inspect the DOM or run code from the console.
New Editor
Developers are only as good as their editors enable them to be. Well sort of. If the editor isn’t very good, productivity can drop dramatically. In many other Sencha products, we’re using Ace editor, so we switched Fiddle 2 from CodeMirror to Ace. The new editor in Fiddle 2 now has code linting right in the editor which is handy for catching issues before you run the code. Like many editors you may already use, the new editor will also show you where the caret is currently located, which is useful when debugging an error when you run the code. It indicates on which line and column the error occurred.
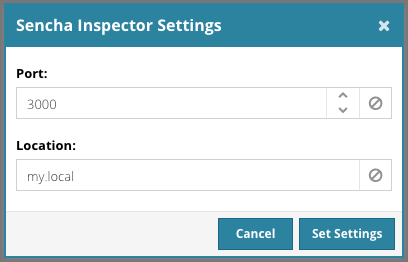
Sencha Inspector Integration
Fiddle 1 and Sencha Inspector had some duplicate functionality. However, the Fiddle inspection features were not updated as Ext JS evolved, and the Fiddle 1 UI was sometimes cumbersome to use. We removed the Fiddle inspection features in favor of a simple checkbox enabling a connection to Sencha Inspector, which does a much better job at inspecting an Ext JS application. When you run the code in Fiddle and the checkbox is checked, Inspector will update to show the fiddle in its list of applications. If you need to edit the URL or port of your local Inspector, you can right-click on the Sencha Inspector item to configure this.
Forking Improvements
A very common thing we do is fork a fiddle – meaning we have a saved fiddle and we want to clone it so we can make changes without affecting the original fiddle. Fiddle 1 would fork the fiddle at the database level, so any changes you made were lost. The new fiddle was a clone of the saved fiddle, discarding any changes you may have made. This was frustrating as you may have made a lot of changes (maybe in more than one file), and you’d remember those changes would be lost immediately after you forked the fiddle. Fiddle 2 improves on this process. Fiddles are now forked at the browser level, so any changes you made will now be included in the newly created fiddle.
Guides
Any tool is only as good as its documentation. And even though Fiddle 2 is simple to use, there are advanced features that do require documentation. For example, we always have to refer to the data guide to see how to use data templating. But now, we have a guide for that. With our dedicated documentation team, we now have a set of guides for simple features as well as the more advanced features. You can read through the guides.
New Server
The Fiddle 1 server was created using the PHP language along with a small PHP framework, and we used its ORM database layer. While this worked well, we found that our custom Node.js servers perform much faster. For example, saving a fiddle in Fiddle 2 happens almost instantly.
The Future
Fiddle 2 is a great enhancement to an already very popular tool, but there is always room for improvement. Search is going to get overhauled, but what other kind of things do you want? Any guides that we can create? Let’s discuss this in the forum.
Did you find the content helpful?
 1
1

 0
0

Latest Content

Ext JS 7.8 Has Arrived!
The Sencha team is pleased to announce the latest Ext JS version 7.8 release. Following…
May 13, 2024

React Apps Development Using ReExt with Ext JS Components
The world is moving fast towards online businesses. Businesses are established online via social media,…
May 1, 2024

How to Write Unit Tests with Sencha Test
In modern software development, unit testing has become an essential practice to ensure the quality…
April 19, 2024




